Clasificación de Texto con Python
 Tutor | octubre 29, 2018
Tutor | octubre 29, 2018
Leer el estado de ánimo del texto con aprendizaje automático se denomina análisis de sentimientos, y es uno de los casos de uso más destacados en la clasificación de textos. Esto cae en el campo de investigación muy activo del procesamiento del lenguaje natural (PLN).
Otros casos de uso comunes de clasificación de texto incluyen la detección de spam, el etiquetado automático de las consultas de los clientes y la categorización del texto en temas definidos. ¿Entonces, cómo puedes hacer eso?
Seleccionar un conjunto de datos
Antes de comenzar, echemos un vistazo a los datos que tenemos. Continúe y descargue el conjunto de datos traducido al español del repositorio de aprendizaje automático de UCI.
Este conjunto de datos incluye revisiones etiquetadas de IMDb, Amazon y Yelp. Cada revisión está marcada con una puntuación de 0 para un sentimiento negativo o 1 para un sentimiento positivo.
Extraiga la carpeta en una carpeta de datos y siga adelante y cargue los datos con Pandas:
import pandas as pd
filepath_dict = {'yelp': 'yelp_labelledes.csv',
'amazon': 'amazon_cells_labelledes.csv',
'imdb': 'imdb_labelledes.csv'}
df_list = []
for source, filepath in filepath_dict.items():
df = pd.read_csv(filepath, names=['sentence', 'label'], sep='\t')
df['source'] = source # Add another column filled with the source name
df_list.append(df)
df = pd.concat(df_list)
print(df.iloc[0])
El resultado debería ser el siguiente:
sentence Así que no hay manera de que lo conecte aquí e... label 0 source amazon Name: 0, dtype: object
Con este conjunto de datos, puede entrenar un modelo para predecir el sentimiento de una oración.
Una forma en que podría hacer esto es contar la frecuencia de cada palabra en cada oración y vincular esta cuenta al conjunto completo de palabras en el conjunto de datos. Comenzaría tomando los datos y creando un vocabulario de todas las palabras en todas las oraciones. La colección de textos se denomina corpus en PLN.
El vocabulario en este caso es una lista de palabras que aparecieron en nuestro texto donde cada palabra tiene su propio índice. Esto le permite crear un vector para una oración. Luego tomaría la oración que desea vectorizar y cuenta su ocurrencia en el vocabulario. El vector resultante será el vocabulario y un conteo para cada palabra en el vocabulario.
El vector resultante también se llama vector de características. En un vector de características, cada dimensión puede ser una característica numérica o categórica, como por ejemplo la altura de un edificio, el precio de una acción o, en nuestro caso, el conteo de una palabra en un vocabulario. Estos vectores de características son una pieza crucial en ciencia de datos y el aprendizaje automático, ya que el modelo que desea entrenar depende de ellos.
Vamos a ilustrar esto. Imagine que tiene las siguientes dos oraciones:
sentences = ['A Juan le gusta el chocolate', 'Juan odia el chocolate']
A continuación, puede usar CountVectorizer proporcionado por la biblioteca scikit-learn para vectorizar oraciones.
Toma las palabras de cada oración y crea un vocabulario de todas las palabras únicas en las oraciones. Este vocabulario se puede usar para crear un vector de características del conteo de las palabras:
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(min_df=0, lowercase=False) vectorizer.fit(sentences) vectorizer.vocabulary_
Resultado
{u'el': 2, u'odia': 5, u'le': 4, u'gusta': 3, u'Juan': 0, u'chocolate': 1}
Este vocabulario sirve también como un índice de cada palabra. Ahora, puede tomar cada oración y obtener las palabras que aparecen de acuerdo con el vocabulario anterior. El vocabulario consta de las cinco palabras en nuestras oraciones, cada una representa una palabra en el vocabulario. Cuando tome las dos oraciones anteriores y las transforme con CountVectorizer obtendrá un vector que representa el conteo de cada palabra de la oración:
vectorizer.transform(sentences).toarray()
array([[1, 1, 1, 1, 1, 0],
[1, 1, 1, 0, 0, 1]]
Ahora, puede ver los vectores de características resultantes para cada oración basándose en el vocabulario anterior. Por ejemplo, si observa el primer elemento, puede ver que ambos vectores tienen un 1. Esto significa que ambas oraciones tienen una aparición de Juan, que está en primer lugar en el vocabulario.
Esto se considera un modelo de Bolsa de palabras, que es una forma común en la PLN para crear vectores a partir de texto. Cada documento se representa como un vector. Puede usar estos vectores ahora como vectores de características para un modelo de aprendizaje automático. Esto nos lleva a nuestra siguiente parte, definiendo un modelo base.
Definición de un modelo base
Cuando trabaja con aprendizaje automático, un paso importante es definir un modelo de base. Por lo general, esto implica un modelo simple, que luego se usa como una comparación con los modelos más avanzados que desea probar. En este caso, utilizará el modelo base para compararlo con los métodos más avanzados que incluyen redes neuronales (profundas).
Primero, dividirá los datos en un conjunto de entrenamiento y pruebas que le permitirá evaluar la precisión y ver si su modelo se generaliza bien. Esto significa si el modelo puede funcionar bien con datos que no ha visto antes. Esta es una manera de ver si el modelo se adapta en exceso.
El ajuste excesivo es cuando un modelo se entrena demasiado bien en los datos de entrenamiento. Desea evitar el ajuste excesivo, ya que esto significaría que el modelo en su mayoría solo memorizó los datos de entrenamiento. Esto explicaría una gran precisión con los datos de entrenamiento, pero una baja precisión en los datos de prueba.
Comenzamos tomando el conjunto de datos de Yelp que extraemos de nuestro conjunto de datos concatenados. A partir de ahí, tomamos las frases y las etiquetas. Los valores “.values” devuelven una matriz NumPy en lugar de un objeto de pandas, que en este contexto es más fácil de leer:
from sklearn.model_selection import train_test_split df_yelp = df[df['source'] == 'yelp'] sentences = df_yelp['sentence'].values y = df_yelp['label'].values sentences_train, sentences_test, y_train, y_test = train_test_split( sentences, y, test_size=0.25, random_state=1000)
Aquí usaremos nuevamente en el modelo Bolsa de Palabras anterior para vectorizar las oraciones. Puede utilizar de nuevo CountVectorizer para esta tarea. Como es posible que no tenga los datos de prueba disponibles durante el entrenamiento, puede crear el vocabulario utilizando solo los datos del entrenamiento. Usando este vocabulario, puede crear los vectores de características para cada oración del conjunto de entrenamiento y prueba:
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() vectorizer.fit(sentences_train) X_train = vectorizer.transform(sentences_train) X_test = vectorizer.transform(sentences_test) X_train
Resultado
<750x1986 sparse matrix of type '<type 'numpy.int64'>' with 7403 stored elements in Compressed Sparse Row format>
Puede ver que los vectores de características resultantes tienen 750 muestras, que son el número de muestras de entrenamiento que tenemos después de la división para el conjunto de entrenamiento. Cada muestra tiene 1714 dimensiones, que es el tamaño del vocabulario. Además, se puede ver que obtenemos una matriz dispersa.
Este es un tipo de datos que está optimizado para matrices con solo unos pocos elementos que no son cero, que solo realiza un seguimiento de los elementos que no son cero, lo que reduce la carga de memoria.
CountVectorizer realiza la tokenización que separa las oraciones en un conjunto de tokens como se vio anteriormente en el vocabulario. Además, elimina la puntuación y los caracteres especiales y puede aplicar otro preprocesamiento a cada palabra. Si lo desea, puede usar un tokenizador personalizado de la biblioteca NLTK con CountVectorizer o usar cualquier número de personalizaciones para mejorar el rendimiento de su modelo.
El modelo de clasificación que vamos a utilizar es la regresión logística, que es un modelo lineal simple pero poderoso. Es una forma de regresión entre 0 y 1 basada en el vector de características de entrada.
Al especificar un valor de corte (por defecto, 0.5), el modelo de regresión se usa para la clasificación.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print("Precisión:", score)
Puede ver que la regresión logística alcanzó un impresionante 78.8%, pero veamos cómo funciona este modelo en los otros conjuntos de datos que tenemos. En este script, realizamos y evaluamos todo el proceso para cada conjunto de datos que tenemos:
for source in df['source'].unique():
df_source = df[df['source'] == source]
sentences = df_source['sentence'].values
y = df_source['label'].values
sentences_train, sentences_test, y_train, y_test = train_test_split(
sentences, y, test_size=0.25, random_state=1000)
vectorizer = CountVectorizer()
vectorizer.fit(sentences_train)
X_train = vectorizer.transform(sentences_train)
X_test = vectorizer.transform(sentences_test)
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test)
print('Precisión para datos {}: {:.4f}'.format(source, score))
Resultado
Precisión para datos amazon: 0.7960 Precisión para datos imdb: 0.7720 Precisión para datos yelp: 0.7880
¡Genial! Se puede ver que este modelo bastante simple logra una precisión bastante buena. Sería interesante ver si podemos superar este modelo. En la siguiente parte, nos familiarizaremos con las redes neuronales (profundas) y cómo aplicarlas a la clasificación de texto.
Una introducción a las redes neuronales profundas
Si ya está familiarizado con las redes neuronales, siéntase libre de saltar a las partes relacionadas con Keras. En esta sección obtendrá una descripción general de las redes neuronales y su funcionamiento interno, y más adelante verá cómo utilizar las redes neuronales con la excelente biblioteca Keras.
Todo comenzó con un famoso artículo en 2012 por Geoffrey Hinton y su equipo, que superó a todos los modelos anteriores en el famoso ImageNet Challenge.
El desafío podría considerarse la Copa del Mundo en visión por computadora, que consiste en clasificar un gran conjunto de imágenes según las etiquetas dadas. Geoffrey Hinton y su equipo lograron superar a los modelos anteriores utilizando una red neuronal convolucional (CNN), que también cubriremos en este tutorial.
Desde entonces, las redes neuronales se han movido a varios campos que incluyen clasificación, regresión e incluso modelos generativos. Los campos más frecuentes incluyen visión por computadora, reconocimiento de voz y procesamiento de lenguaje natural (PLN).
Las redes neuronales, o algunas veces llamadas redes neuronales artificiales (RNA), son redes computacionales que fueron inspiradas vagamente por las redes neuronales en el cerebro humano. Consisten en neuronas (también llamadas nodos) que están conectadas como en el gráfico a continuación.
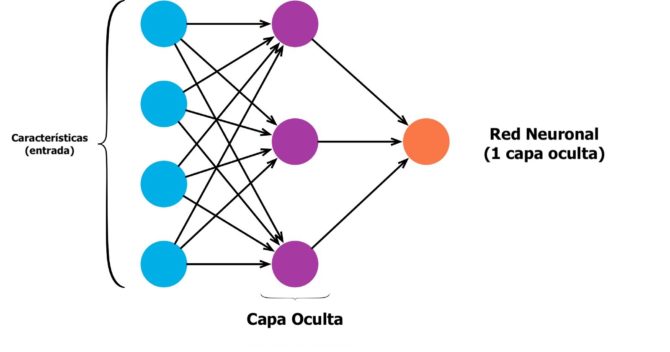
Empieza por tener una capa de neuronas de entrada donde alimenta sus vectores de características y los valores fluyen hacia una capa oculta. En cada conexión, está alimentando el valor hacia adelante, mientras que el valor se multiplica por un peso y se agrega un sesgo al valor. Esto sucede en cada conexión y al final llega a una capa de salida con uno o más nodos de salida.
Si desea tener una clasificación binaria, puede usar un nodo, pero si tiene varias categorías, debe usar varios nodos para cada categoría:
Puede tener tantas capas ocultas como desee. De hecho, una red neuronal con más de una capa oculta se considera una red neuronal profunda.
Es posible que ya se pregunte cómo se calculan los pesos, y esta es obviamente la parte más importante de las redes neuronales, pero también la parte más difícil. El algoritmo comienza con la inicialización de los pesos con valores aleatorios y luego se entrenan con un método llamado backpropagation.
Esto se hace utilizando métodos de optimización como el descenso de gradiente para reducir el error entre la salida calculada y la deseada (también llamada salida objetivo). El error está determinado por una función de pérdida cuya pérdida queremos minimizar con el optimizador. El proceso completo es demasiado extenso para cubrirlo aquí, por lo que puedes verlo más en detalle buscando la web.
Lo que debe saber es que hay varios métodos de optimización que puede usar, pero el optimizador más utilizado actualmente se llama Adam https://arxiv.org/abs/1412.6980, que tiene un buen desempeño en varios problemas.
También puede usar diferentes funciones de pérdida, pero en este tutorial solo necesitará la función de pérdida de entropía cruzada o, más específicamente, la entropía cruzada binaria que se usa para los problemas de clasificación binaria. Asegúrese de experimentar con los diversos métodos y herramientas disponibles. Algunos investigadores incluso afirman en un artículo reciente que la elección de los mejores métodos de rendimiento se parece a la alquimia. La razón es que muchos métodos no están bien explicados y consisten en muchos ajustes y pruebas.
Presentando keras
Keras es una API de aprendizaje profundo y redes neuronales de François Chollet que puede ejecutarse sobre Tensorflow (Google), Theano o CNTK (Microsoft). Citando libro de François Chollet, Deep Learning with Python:
Keras es una biblioteca a nivel de modelo, que proporciona bloques de construcción de alto nivel para desarrollar modelos de aprendizaje profundo. No maneja operaciones de bajo nivel como la manipulación y diferenciación del tensor. En su lugar, se basa en una biblioteca tensorial especializada y bien optimizada para hacerlo, que funciona como el motor de fondo de Keras
Es una excelente manera de comenzar a experimentar con redes neuronales sin tener que implementar cada capa y pieza por su cuenta. Por ejemplo, Tensorflow es una gran biblioteca de aprendizaje automático, pero tiene que implementar una gran cantidad de código repetitivo para tener un modelo en ejecución.
Instalando keras
Antes de instalar Keras, necesitará Tensorflow, Theano o CNTK. En este tutorial usaremos Tensorflow, pero no dude en utilizar cualquiera de los marcos que mejor se adapten a sus necesidades. Keras se puede instalar usando PyPI con el siguiente comando:
pip install keras
Puede elegir el backend que desea tener abriendo el archivo de configuración de Keras que puede encontrar aquí:
$USUARIO/.keras/keras.json
El archivo de configuración debería verse así:
{
"image_data_format": "channels_last",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Puede cambiar el campo de backend allí a “theano”, “tensorflow” o “cntk” dependiendo de cuál tenga instalado.
Su primer modelo de Keras
Ahora ya estás listo para experimentar con Keras. Keras soporta dos tipos principales de modelos. Tiene la API del modelo secuencial que verá en uso en este tutorial y la API funcional que puede hacer todo el modelo secuencial, pero también puede usarse para modelos avanzados con arquitecturas de red complejas.
El modelo secuencial es una pila lineal de capas, donde puede usar la gran variedad de capas disponibles en Keras. La capa más común es la capa Densa, que es su capa de red neuronal densamente conectada con todos los pesos y sesgos con los que ya está familiarizado.
Veamos si podemos lograr alguna mejora en nuestro modelo de regresión logística anterior. Puede usar las matrices X_train y X_test que creó en nuestro ejemplo anterior.
Antes de construir nuestro modelo, necesitamos conocer la dimensión de entrada de nuestros vectores de características. Esto sucede solo en la primera capa, ya que las siguientes capas pueden hacer inferencia de forma automática. Para construir el modelo secuencial, puede agregar capas una por una en el orden siguiente:
from keras.models import Sequential from keras import layers input_dim = X_train.shape[1] # Numero de características model = Sequential() model.add(layers.Dense(10, input_dim=input_dim, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
Antes de que pueda comenzar con el entrenamiento del modelo, debe configurar el proceso de aprendizaje. Esto se hace con el método .compile(). Este método especifica el optimizador y la función de pérdida.
Además, puede agregar una lista de métricas que luego se pueden usar para la evaluación, pero no influyen en el entrenamiento. En este caso, queremos utilizar una entropía cruzada binaria y el optimizador Adam que hemos mencionado anteriormente. Keras también incluye una práctica función .summary() para ofrecer una visión general del modelo y el número de parámetros disponibles para el entrenamiento:
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
Resultado
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 10) 19870 _________________________________________________________________ dense_2 (Dense) (None, 1) 11 ================================================================= Total params: 19,881 Trainable params: 19,881 Non-trainable params: 0 _________________________________________________________________
Puede notar que tenemos 9935 parámetros para la primera capa y otros 6 en la siguiente. ¿De dónde vienen?
Tenemos 19870 dimensiones para cada vector de característica, y luego tenemos 5 nodos. Necesitamos ponderaciones para cada dimensión de la característica y cada nodo representa 1985 * 5 = 9930 parámetros, y luego tenemos otras 5 de un sesgo adicional para cada nodo, lo que nos permite obtener los 9935 parámetros.
En el nodo final, tenemos otros 5 pesos y un sesgo, lo que nos da 6 parámetros.
Ahora es el momento de comenzar el entrenamiento con la función .fit().
Dado que el entrenamiento en redes neuronales es un proceso iterativo, el entrenamiento no se detiene una vez que se hace una vez. Tiene que especificar el número de iteraciones que desea que el modelo entrene.
Esas iteraciones son comúnmente llamadas épocas. Queremos ejecutar el entrenamiento durante 100 épocas para poder ver cómo cambia la precisión después de cada época.
Otro parámetro que tiene para su selección es el tamaño del lote. El tamaño del lote es responsable de la cantidad de muestras que queremos usar en una época, lo que significa cuántas muestras se usan en una pasada hacia adelante / hacia atrás.
Esto aumenta la velocidad del cálculo, ya que necesita menos épocas para correr, pero también necesita más memoria, y el modelo puede degradarse con tamaños de lotes más grandes. Ya que tenemos un pequeño grupo de entrenamiento, podemos dejar esto en un tamaño de lote bajo:
history = model.fit(X_train, y_train,
epochs=50,
verbose=False,
validation_data=(X_test, y_test),
batch_size=10)
Ahora puede usar el método .evaluate() para medir la precisión del modelo. Puede hacer esto tanto para los datos de entrenamiento como para los datos de prueba. Esperamos que los datos de entrenamiento tengan una mayor precisión que los datos de prueba. Minetras más entrene una red neuronal, más probable es que comience a tener overfitting (sobreajuste).
Tenga en cuenta que si vuelve a ejecutar el método .fit(), comenzará con los pesos calculados del entrenamiento anterior. Asegúrese de volver a compilar el modelo antes de comenzar a entrenarlo nuevamente.
Ahora evaluemos el modelo de precisión:
loss, accuracy = model.evaluate(X_train, y_train, verbose=False)
print("Precisión Entrenamiento: {:.4f}".format(accuracy))
loss, accuracy = model.evaluate(X_test, y_test, verbose=False)
print("Precisión Prueba: {:.4f}".format(accuracy))
Ya se puede ver que el modelo tuvo overfitting ya que alcanzó el 100% de precisión para el conjunto de entrenamiento. Pero esto se esperaba ya que el número de épocas era bastante grande para este modelo. Sin embargo, la precisión del conjunto de pruebas ya ha superado nuestra regresión logística anterior con el modelo “Bag of Words”, que es un gran paso más en términos de nuestro progreso.
Para hacer su vida más fácil, puede usar esta pequeña función auxiliar para visualizar la pérdida y la precisión de los datos de entrenamiento y pruebas basados en el historial (history).
Esta llamada, que se aplica automáticamente a cada modelo de Keras, registra la pérdida y las métricas adicionales que se pueden agregar en el método .fit(). En este caso, solo nos interesa la precisión. Esta función auxiliar emplea la biblioteca matplotlib:
import matplotlib.pyplot as plt
plt.style.use('ggplot') #
def plot_history(history):
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
x = range(1, len(acc) + 1)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x, acc, 'b', label='Entrenamiento prec')
plt.plot(x, val_acc, 'r', label='Validacion prec')
plt.title('Precision Entrenamiento y validacion')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(x, loss, 'b', label='Perdida Entrenamiento')
plt.plot(x, val_loss, 'r', label='Perdida Validacion')
plt.title('Perdida Entrenamiento y validacion')
plt.legend()
plt.show()
Para usar esta función, simplemente llame a plot_history():
plot_history(history)
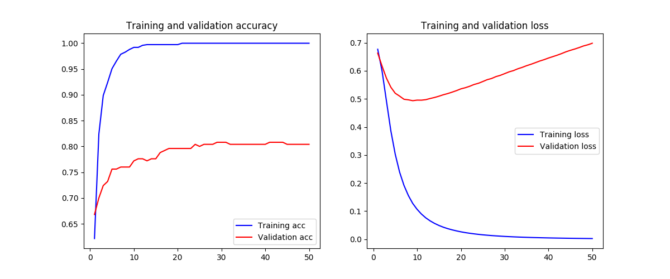
Puede ver que hemos sobre-entrenado a nuestro modelo desde que el conjunto de entrenamiento alcanzó el 100% de precisión.
Una buena manera de ver cuándo el modelo comienza a funcionar excesivamente es cuando la pérdida de los datos de validación comienza a aumentar nuevamente. Esto tiende a ser un buen punto para detener el modelo. Puede ver que esto pasa cerca de las 15-25 épocas.
En este caso, nuestro conjunto de pruebas y validación es el mismo, ya que tenemos un tamaño de muestra más pequeño. Como hemos cubierto anteriormente, las redes neuronales (profundas) funcionan mejor cuando se tiene una gran cantidad de muestras. En la siguiente parte, verá una forma diferente de representar palabras como vectores. Esta es una forma muy emocionante y poderosa de trabajar con palabras en la que verá cómo representar palabras como vectores densos.
Written by Tutor
Related View More
Tutor | octubre 28, 2018
Predicciones simples con Python
Tutor | octubre 28, 2018
Procesamiento y Transformación de Datos en Python
Tutor | octubre 28, 2018
Análisis exploratorio en Python con Pandas
Tutor | octubre 28, 2018
Bibliotecas para hacer análisis de datos en Python
Tutor | octubre 28, 2018
Estructuras de Datos, Iteraciones y Condicionales en Python
Tutor | octubre 28, 2018
Análisis de Datos con Python – Una Introducción
Tutor | marzo 11, 2022
Estructura y Etiquetas en HTML5
Tutor | marzo 11, 2022
Conceptos básicos de desarrollo web
Tutor | marzo 9, 2022