Análisis exploratorio en Python con Pandas
 Tutor | octubre 28, 2018
Tutor | octubre 28, 2018
Pandas es una de las bibliotecas de análisis de datos más útiles de Python. Ha sido fundamentales para aumentar el uso de Python en la comunidad de la ciencia de datos.
Ahora usaremos Pandas para leer un conjunto de datos, realizar análisis exploratorios y crear nuestro primer algoritmo de categorización básico para resolver este problema.
Antes de cargar los datos, entendamos las 2 estructuras de datos clave en Pandas – Series y DataFrames.
Series y Dataframes
Las series pueden entenderse como una matriz etiquetada / indexada de 1 dimensión. Puede acceder a elementos individuales de esta serie a través de estas etiquetas.
Un dataframe es similar al libro de Excel: tiene nombres de columnas que se refieren a columnas y filas, a las que se puede acceder mediante el uso de números de fila. La diferencia esencial es que los nombres de columna y los números de fila se conocen como índice de columna y fila, en el caso de los marcos de datos.
Las series y los dataframes forman el modelo de datos central para Pandas en Python. Los conjuntos de datos se leen primero en estos marcos de datos y luego varias operaciones (por ejemplo, agrupación, agregación, etc.) se pueden aplicar muy fácilmente a sus columnas.
Demostraremos los principales métodos en acción al analizar un conjunto de datos sobre la tasa de abandono de los clientes de los operadores de telecomunicaciones. Leamos los datos (usando read_csv), y echemos un vistazo a las primeras 5 líneas usando el método head():
import pandas as pd
import numpy as np
df = pd.read_csv('../../data/telecom_churn.csv')
df.head()
# cambia la dirección '../../data/telecom_churn.csv' a la tuya

Recuerde que cada fila corresponde a un cliente, el objeto de nuestra investigación y las columnas son características del objeto.
Vamos a echar un vistazo a la dimensionalidad de los datos, nombres de características y tipos de características.
print(df.shape) (3333, 20)
Desde la salida, podemos ver que la tabla contiene 3333 filas y 20 columnas. Ahora intentemos ver los nombres de las columnas usando columnas:
print(df.columns)
Index(['State', 'Account length', 'Area code', 'International plan',
'Voice mail plan', 'Number vmail messages', 'Total day minutes',
'Total day calls', 'Total day charge', 'Total eve minutes',
'Total eve calls', 'Total eve charge', 'Total night minutes',
'Total night calls', 'Total night charge', 'Total intl minutes',
'Total intl calls', 'Total intl charge', 'Customer service calls',
'Churn'],
dtype='object')
Podemos usar el método info() para generar información general sobre el marco de datos:
print(df.info())
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3333 entries, 0 to 3332 Data columns (total 20 columns): State 3333 non-null object Account length 3333 non-null int64 Area code 3333 non-null int64 International plan 3333 non-null object Voice mail plan 3333 non-null object Number vmail messages 3333 non-null int64 Total day minutes 3333 non-null float64 Total day calls 3333 non-null int64 Total day charge 3333 non-null float64 Total eve minutes 3333 non-null float64 Total eve calls 3333 non-null int64 Total eve charge 3333 non-null float64 Total night minutes 3333 non-null float64 Total night calls 3333 non-null int64 Total night charge 3333 non-null float64 Total intl minutes 3333 non-null float64 Total intl calls 3333 non-null int64 Total intl charge 3333 non-null float64 Customer service calls 3333 non-null int64 Churn 3333 non-null bool dtypes: bool(1), float64(8), int64(8), object(3) memory usage: 498.1+ KB None
bool, int64, float64 y object son los tipos de datos de nuestras funciones. Vemos que una característica es lógica (bool), 3 características son de tipo objeto y 16 características son numéricas.
Con este mismo método, podemos ver fácilmente si hay valores faltantes. Aquí, no hay ninguno porque cada columna contiene 3333 observaciones, el mismo número de filas que vimos antes con forma.
Podemos cambiar el tipo de columna con el método astype. Apliquemos este método a la función Churn para convertirlo en int64:
df['Churn'] = df['Churn'].astype('int64')
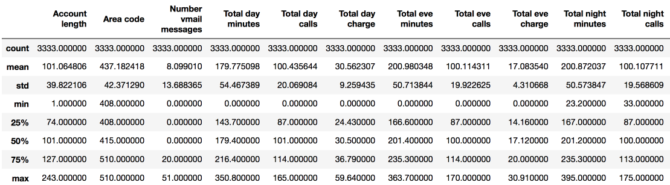
El método descrito muestra las características estadísticas básicas de cada característica numérica (tipos int64 y float64): número de valores no perdidos, media, desviación estándar, rango, mediana, cuartiles 0.25 y 0.75.
df.describe()
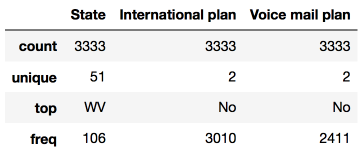
Para ver estadísticas sobre características no numéricas, uno tiene que indicar explícitamente los tipos de datos de interés en el parámetro de inclusión.
df.describe(include=['object', 'bool'])
Ordenar los datos
Un DataFrame se puede ordenar por el valor de una de las variables (es decir, columnas). Por ejemplo, podemos ordenar el cargo por día total (use ascendente = Falso para clasificar en orden descendente):
df.sort_values(by='Total day charge', ascending=False).head()
Alternativamente, también podemos ordenar por múltiples columnas:
df.sort_values(by=['Churn', 'Total day charge'], ascending=[True, False]).head()
Indexación y recuperación de datos
Los DataFrame se pueden indexar de diferentes maneras.
Para obtener una sola columna, puede utilizar una construcción DataFrame [‘Nombre’]. Usemos esto para responder solo a una pregunta sobre esa columna: ¿cuál es la proporción de usuarios afectados en nuestro marco de datos?
df['Churn'].mean() 0.14491449144914492
El 14.5% es bastante malo para una empresa; tal tasa de deserción puede hacer que la empresa quiebre.
La indexación booleana con una columna también es muy conveniente. La sintaxis es df[P(df[‘Name’])], donde P es una condición lógica que se comprueba para cada elemento de la columna Nombre. El resultado de dicha indexación es el DataFrame que consiste solo en filas que satisfacen la condición P en la columna Nombre.
Vamos a usarlo para responder a la pregunta:
¿Cuáles son los valores promedio de las variables para los usuarios?
df[df['Churn'] == 1].mean() Account length 102.664596 Area code 437.817805 Number vmail messages 5.115942 Total day minutes 206.914079 Total day calls 101.335404 Total day charge 35.175921 Total eve minutes 212.410145 Total eve calls 100.561077 Total eve charge 18.054969 Total night minutes 205.231677 Total night calls 100.399586 Total night charge 9.235528 Total intl minutes 10.700000 Total intl calls 4.163561 Total intl charge 2.889545 Customer service calls 2.229814 Churn 1.000000 dtype: float64
¿Cuánto tiempo (en promedio) pasan los usuarios agitados en el teléfono durante el día?
df[df['Churn'] == 1]['Total day minutes'].mean() 206.91407867494814
¿Cuál es la duración máxima de las llamadas internacionales entre usuarios leales (Churn == 0) que no tienen un plan internacional?
df[(df['Churn'] == 0) & (df['International plan'] == 'No')]['Total intl minutes'].max() 18.899999999999999
Los dataframes se pueden indexar por nombre de columna (etiqueta) o por nombre de fila (índice) o por el número de serie de una fila. El método loc se usa para indexar por nombre, mientras que iloc () se usa para indexar por número.
df.loc[0:5, 'State':'Area code'] df.iloc[0:5, 0:3]
Si necesitamos la primera o la última línea del marco de datos, usamos la sintaxis df[:1] o df [-1:].
Written by Tutor
Related View More
Tutor | octubre 29, 2018
Clasificación de Texto con Python
Tutor | octubre 28, 2018
Predicciones simples con Python
Tutor | octubre 28, 2018
Procesamiento y Transformación de Datos en Python
Tutor | octubre 28, 2018
Bibliotecas para hacer análisis de datos en Python
Tutor | octubre 28, 2018
Estructuras de Datos, Iteraciones y Condicionales en Python
Tutor | octubre 28, 2018
Análisis de Datos con Python – Una Introducción
Tutor | marzo 11, 2022
Estructura y Etiquetas en HTML5
Tutor | marzo 11, 2022
Conceptos básicos de desarrollo web
Tutor | marzo 9, 2022