Aprendizaje profundo y el aprendizaje de máquina tradicional

Uno de los principales desafíos encontrados en los modelos tradicionales de aprendizaje automático es un proceso llamado extracción de características. El programador debe ser específico y decirle a la computadora las características que debe tener en cuenta. Estas características ayudarán a tomar decisiones.
El ingreso de datos sin procesar en el algoritmo rara vez funciona, por lo que la extracción de características es una parte crítica del flujo de trabajo de aprendizaje automático tradicional.
Esto coloca una gran responsabilidad en el programador, y la eficiencia del algoritmo se basa en gran medida en la inventiva del programador. Para problemas complejos, como el reconocimiento de objetos o el reconocimiento de escritura a mano, este es un gran problema.
El aprendizaje profundo, con la capacidad de aprender múltiples capas de representación, es uno de los pocos métodos que nos ha ayudado con la extracción automática de características. Se puede suponer que las capas inferiores realizan la extracción automática de características, lo que requiere poca o ninguna guía del programador.
La red neuronal artificial, o simplemente la red neuronal para abreviar, no es una idea nueva. Ha existido por cerca de 80 años.
No fue hasta 2011, cuando Deep Neural Networks se hizo popular con el uso de nuevas técnicas, la enorme disponibilidad de conjuntos de datos y las potentes computadoras.
Una red neuronal imita una neurona, que tiene dendritas, un núcleo, un axón y un axón terminal.
Para una red, necesitamos dos neuronas. Estas neuronas transfieren información a través de la sinapsis entre las dendritas de una y el axón terminal de otra.
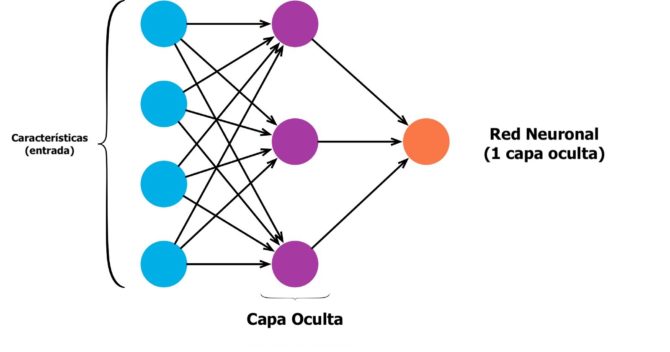
Los círculos son neuronas o nodos, con sus funciones en los datos y las líneas / bordes que los conectan son los pesos / información que se están transmitiendo.
Cada columna es una capa. La primera capa de sus datos es la capa de entrada. Luego, todas las capas entre la capa de entrada y la capa de salida son las capas ocultas.
Si tienes una o unas pocas capas ocultas, entonces tienes una red neuronal poco profunda. Si tienes muchas capas ocultas, entonces tienes una red neuronal profunda.
En este modelo, tienes datos de entrada, los pesas y los pasas a través de la función en la neurona que se llama función de umbral o función de activación.
Básicamente, es la suma de todos los valores después de compararlo con un cierto valor. Si dispara una señal, entonces el resultado es (1) fuera, o no se dispara nada, entonces (0). Luego se ponderan y pasan a la siguiente neurona, y se ejecuta el mismo tipo de función.
Podemos tener una función sigmoide (forma de s) como función de activación.
En cuanto a los pesos, son aleatorios para comenzar, y son únicos por entrada en el nodo / neurona.
En un “feed forward” típico, el tipo más básico de red neuronal, su información pasa directamente a través de la red que creó y compara la salida con lo que esperaba que la salida hubiera estado usando sus datos de muestra.
Desde aquí, debe ajustar los pesos para ayudarlo a obtener su salida para que coincida con la salida deseada.
El acto de enviar datos directamente a través de una red neuronal se denomina red neuronal de avance o “feed forward neural network” en inglés.
Nuestros datos van desde la entrada, a las capas, en orden, luego a la salida.
Cuando retrocedemos y comenzamos a ajustar los pesos para minimizar la pérdida / costo, esto se denomina propagación por retroceso o “back propagation” en inglés.
Este es un problema de optimización. Con la red neuronal, en la práctica real, tenemos que lidiar con cientos de miles de variables, o millones, o más.
La primera solución fue utilizar el descenso de gradiente estocástico como método de optimización. Ahora, hay opciones como AdaGrad, Adam Optimizer, etc. De cualquier manera, esta es una operación computacional masiva. Es por eso que las redes neuronales se dejaron en su mayoría en el estante durante más de medio siglo. Fue solo muy recientemente que incluso tuvimos el poder y la arquitectura en nuestras máquinas para considerar realizar estas operaciones y los conjuntos de datos del tamaño adecuado para coincidir.
Para tareas de clasificación simples, la red neuronal tiene un rendimiento relativamente cercano a otros algoritmos simples como K Vecinos más cercanos. La utilidad real de las redes neuronales se realiza cuando tenemos datos mucho más grandes y preguntas mucho más complejas, las cuales superan a otros modelos de aprendizaje automático.
Written by Tutor
Related View More
Pasos para entrenar una red neuronal profunda
Redes neuronales profundas – Tipos y Características
Requerimientos para Aprendizaje Profundo en Python
Estructura y Etiquetas en HTML5
Conceptos básicos de desarrollo web
Hadoop Explicado
Procesamiento Básico de Datos con Python
Los modelos de datos en una base de datos